CQRS (by Martin Fowler)
대하여
- 본 내용은 Martin Fowler가 블로그에 작성한 내용을 번역한 것입니다.
- Origin Url: CQRS
CQRS
CQRS는 명령 쿼리 책임 분리(Command Query Responsibility Segregation)를 나타냅니다. Greg Young이 처음 설명한 패턴입니다. 핵심은 정보를 읽는 데 사용하는 모델과 다른 모델을 사용하여 정보를 업데이트할 수 있다는 개념입니다. 일부 상황에서는 이러한 분리가 유용할 수 있지만 대부분의 시스템에서 CQRS는 위험한 복잡성을 추가한다는 점에 유의하십시오.
사람들이 정보 시스템과 상호 작용하기 위해 사용하는 주류 접근 방식은 정보 시스템을 CRUD 데이터 저장소로 취급하는 것입니다. 이것은 우리가 새로운 레코드를 생성(create)하고, 레코드를 읽고(read), 기존 레코드를 수정(update)하고, 작업이 끝나면 레코드를 삭제(delete)할 수 있는 일부 레코드 구조의 멘탈 모델이 있음을 의미합니다. 가장 간단한 경우, 우리의 상호 작용은 모두 이러한 레코드를 저장하고 검색하는 것입니다.
우리의 요구 사항이 더욱 복잡해짐에 따라 우리는 그 모델에서 꾸준히 멀어지고 있습니다. 여러 레코드를 하나로 축소하거나 다른 장소에 대한 정보를 결합하여 가상 레코드를 형성하는 등 레코드 저장소와 다른 방식으로 정보를 볼 수 있습니다. 업데이트 측면에서 특정 데이터 조합만 저장하도록 허용하는 유효성 검사 규칙을 찾을 수 있으며, 심지어 우리가 제공하는 것과 다른 저장 데이터를 유추할 수도 있습니다.
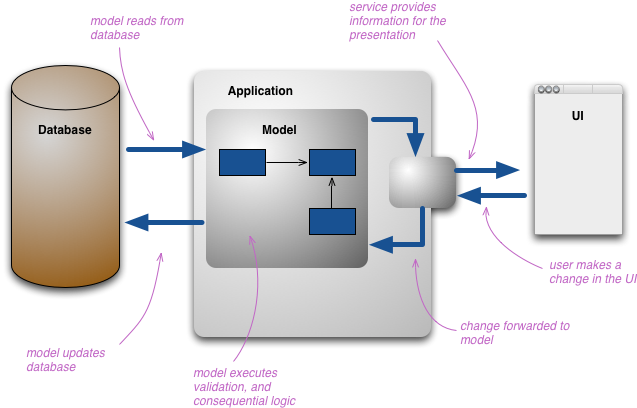
이것이 발생함에 따라 우리는 정보의 여러 표현을 보기 시작합니다. 사용자가 정보와 상호 작용할 때 이 정보의 다양한 표현을 사용하며, 각각은 서로 다른 표현입니다. 개발자는 일반적으로 모델의 핵심 요소를 조작하는 데 사용하는 자체 개념 모델을 구축합니다. 도메인 모델을 사용하는 경우 이는 일반적으로 도메인의 개념적 표현입니다. 또한 일반적으로 영구 저장소를 가능한 한 개념적 모델에 가깝게 만듭니다.
표현의 다중 레이어 구조는 매우 복잡해질 수 있지만 사람들이 이 작업을 수행할 때 여전히 모든 프레젠테이션 간의 개념적 통합 지점 역할을 하는 단일 개념적 표현으로 해결합니다.
CQRS가 도입한 변경 사항은 해당 개념적 모델을 업데이트 및 표시를 위해 별도의 모델로 분할하는 것입니다. 이를 CommandQuerySeparation의 용어에 따라 각각 Command 및 Query라고 합니다. 그 근거는 특히 더 복잡한 도메인에서 많은 문제의 경우 명령과 쿼리에 대해 동일한 개념적 모델을 사용하면 둘 다 제대로 작동하지 않는 더 복잡한 모델로 이어지기 때문입니다.
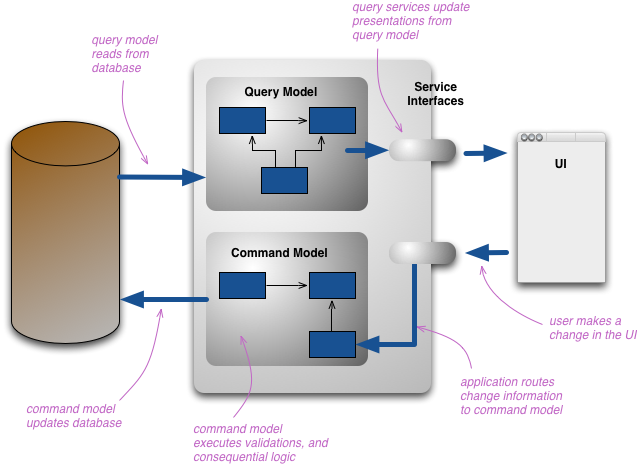
별도의 모델은 가장 일반적으로 서로 다른 논리적 프로세스, 아마도 별도의 하드웨어에서 실행되는 서로 다른 개체 모델을 의미합니다. 웹 예제에서는 쿼리 모델을 사용하여 렌더링된 웹 페이지를 보고 있는 사용자를 볼 수 있습니다. 변경 사항이 처리를 위해 별도의 명령 모델로 라우팅되는 변경을 시작하면 결과 변경 사항이 쿼리 모델에 전달되어 업데이트된 상태를 렌더링합니다.
여기에 상당한 변화의 여지가 있습니다. 인메모리 모델은 동일한 데이터베이스를 공유할 수 있으며, 이 경우 데이터베이스는 두 모델 간의 통신 역할을 합니다. 그러나 별도의 데이터베이스를 사용하여 쿼리 측 데이터베이스를 실시간 ReportingDatabase로 효과적으로 만들 수도 있습니다. 이 경우 두 모델 또는 해당 데이터베이스 간에 통신 메커니즘이 있어야 합니다.
두 모델은 별도의 개체 모델이 아닐 수 있습니다. 동일한 개체가 관계형 데이터베이스의 보기와 같이 명령(command) 측과 쿼리(query) 측에서 서로 다른 인터페이스를 가질 수 있습니다. 그러나 일반적으로 CQRS에 대해 들었을 때 그들은 분명히 별개의 모델입니다.
CQRS는 자연스럽게 일부 다른 아키텍처 패턴에 맞습니다.
- CRUD를 통해 상호 작용하는 단일 표현에서 멀어짐에 따라 작업 기반 UI로 쉽게 이동할 수 있습니다.
- CQRS는 이벤트 기반 프로그래밍 모델에 잘 맞습니다. CQRS 시스템이 Event Collaboration과 통신하는 별도의 서비스로 분할되는 것을 보는 것이 일반적입니다. 이를 통해 이러한 서비스는 이벤트 소싱을 쉽게 활용할 수 있습니다.
- 별도의 모델을 사용하면 해당 모델을 일관성 있게 유지하는 것이 얼마나 어려운지에 대한 질문이 제기되어 최종 일관성을 사용할 가능성이 높아집니다.
- 많은 도메인의 경우 업데이트할 때 많은 논리가 필요하므로 EagerReadDerivation을 사용하여 쿼리 측 모델을 단순화하는 것이 합리적일 수 있습니다.
- 쓰기 모델이 모든 업데이트에 대한 이벤트를 생성하는 경우 읽기 모델을 EventPosters로 구성하여 MemoryImage가 되도록 하여 많은 데이터베이스 상호 작용을 피할 수 있습니다.
- CQRS는 Domain-Driven Design의 혜택을 받는 종류인 복잡한 도메인에 적합합니다.
사용 시기
다른 패턴과 마찬가지로 CQRS는 어떤 곳에서는 유용하지만 다른 곳에서는 유용하지 않습니다. 많은 시스템이 CRUD 멘탈 모델에 적합하므로 해당 스타일로 수행되어야 합니다. CQRS는 관련된 모든 사람들에게 상당한 정신적 도약(mental leap)이므로, 점프할 가치가 있는 경우가 아니면 사용해서는 안 됩니다. 나는 CQRS를 성공적으로 사용했지만 지금까지 내가 겪은 대부분의 경우는 그다지 좋지 않았으며 CQRS는 소프트웨어 시스템을 심각한 어려움에 빠뜨리는 중요한 힘으로 여겨졌습니다.
특히, CQRS는 시스템 전체가 아닌 시스템의 특정 부분(DDD 용어의 BoundedContext)에서만 사용해야 합니다. 이러한 사고 방식에서 각 Bounded Context는 모델링 방법에 대한 자체 결정이 필요합니다.
지금까지 나는 두 가지 방향에서 이점을 보았습니다. 첫째는 CQRS를 사용하여 몇 가지 복잡한 도메인을 다루기가 더 쉬울 수 있다는 것입니다. 그러나 CQRS에 대한 그러한 적합성은 극히 소수의 경우입니다. 일반적으로 모델을 공유하는 것이 더 쉬울 정도로 명령 측과 쿼리 측 사이에 충분한 겹침이 있습니다. 일치하지 않는 도메인에서 CQRS를 사용하면 복잡성이 추가되어 생산성이 감소하고 위험이 증가합니 다른 주요 이점은 고성능 응용 프로그램을 처리하는 것입니다. CQRS를 사용하면 읽기 및 쓰기에서 로드를 분리하여 각각을 독립적으로 확장할 수 있습니다. 애플리케이션에서 읽기와 쓰기 사이에 큰 차이가 있는 경우 이는 매우 편리합니다. 그것 없이도 양쪽에 서로 다른 최적화 전략을 적용할 수 있습니다. 이에 대한 예는 읽기 및 업데이트에 서로 다른 데이터베이스 액세스 기술을 사용하는 것입니다.
도메인이 CQRS에 적합하지 않지만 복잡성이나 성능 문제를 추가하는 까다로운 쿼리가 있는 경우에도 ReportingDatabase를 사용할 수 있음을 기억하십시오. CQRS는 모든 쿼리에 대해 별도의 모델을 사용합니다. Reporting Database를 사용하면 대부분의 쿼리에 여전히 기본 시스템을 사용하지만 더 까다로운 쿼리는 Reporting Database를 사용합니다.
이러한 이점에도 불구하고 CQRS를 사용할 때는 매우 신중해야 합니다. 많은 정보 시스템은 읽는 것과 동일한 방식으로 업데이트되는 정보 기반의 개념에 잘 맞습니다. 이러한 시스템에 CQRS를 추가하면 상당한 복잡성이 추가될 수 있습니다. 유능한 팀에서 관리하더라도 프로젝트에 의미없는 위험(risk)을 추가하여 생산성을 크게 떨어뜨리는 경우를 확실히 보았습니다. 따라서 CQRS는 좋은 패턴이지만, 잘 사용하기 어렵고 잘못 취급하면 오히려 잃을게 많다는 점에 유의하십시오.